CD Biosynsis is a leader in using artificial intelligence to advance enzyme engineering. With a professional team of scientists, we have long been dedicated to providing researchers with targeted enzyme evolution and design services. As artificial intelligence has been widely used in various fields in recent years, our EnzymoGeniusTM platform also applies artificial intelligence in the high-throughput enzyme screening process to accelerate the discovery of enzyme mutants.
Overview
As we all know, to develop an AI-led application project, the first step towards AI training is data collection. The importance of data collection as the first stage of an AI project cannot be overstated, and obtaining a good database is the key to AI application development. Without access to data with good quality assurance, the subsequent development work of the AI project will be difficult to achieve the desired results. Data collection is the basis for training AI models, and the quality of data collection is almost decisive for the performance of the final AI development application model, so we should fully ensure the completeness and accuracy of the data when collecting data.
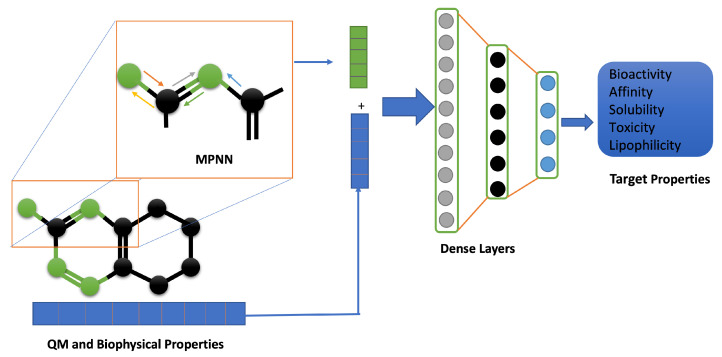 Fig. 1 Physics-informed ML framework for predictive modeling. (Joshi RP, et al., 2021)
Fig. 1 Physics-informed ML framework for predictive modeling. (Joshi RP, et al., 2021)
Our Services
Our EnzymoGeniusTM platform is dedicated to the directed evolution and design of enzymes. Combined with our advantages in AI, we are able to provide our customers with AI data collection of high-throughput enzyme mutant screening libraries.
There are three main methods for the construction of our enzyme mutant libraries: random mutation, targeted mutation and genetic recombination.
- Random Mutation consists of two types: in vivo random mutation mediated by strain mutagenesis and in vitro random mutation represented by error-prone PCR. In vitro random mutagenesis can be realized on the basis of PCR in the following ways. Firstly, the fidelity during DNA polymerization can be reduced by DNA interfering substances. Secondly, error-prone DNA polymerase can also be used directly to interfere with the DNA polymerization process. In addition, the normal polymerization of DNA can be affected by lowering the template concentration, putting in dNTP analogues or dNTP with an imbalance in proportion. The obtained mutant DNA products are then recombined and transformed to complete the preparation of mutant libraries.
- Targeted Mutation is based on a large amount of experimental data, literature, or computer-assisted to identify the key amino acid sites, and then targeted design and introduction of mutations. The most convenient way to prepare targeted mutation libraries is to design parsimonious primers, on which the bases of the target region are randomly arranged, and all types of specific triplet codons of proteins including terminators will be possible.
- Genetic Recombination is the process of recombining DNA fragments from different sources to form new DNA molecules or genes. There are generally two sources of DNA fragments in the construction of mutation libraries, one is the DNA of homologous enzyme proteins, which can be enhanced by codon optimization when the sequence identity is insufficient, and the other is the DNA of different mutants, which can be used as a complement to the random mutation and fixed-point mutation libraries.
Advantages of Our Services
- Rich Data Types
Based on our enzyme mutant library construction technology, we can provide a rich variety of data for AI model development to meet the needs of AI learning and training.
- Accurate Data Quality
our data collection guarantees a high degree of accuracy and consistency, which is especially suitable for model training for subsequent AI, providing a good foundation for efficient AI application project development.
- Sufficient Amount of Data
For the training of AI models, it is essential to provide sufficient amount of data, and we are able to provide a sufficient number of enzyme mutation libraries to have sufficient accuracy in the subsequent training of AI models.
- Reliable Data Sources
We conduct data collection to ensure that the data sources are reliable and do not contain any sensitive information or copyright violations.
With a professional scientific team, CD Biosynsis has been dedicated to providing researchers with enzyme directed evolution and design services. Combined with the advantages of Artificial Intelligence, we use AI to guide enzyme variant discovery and screen for ideal enzyme variants. If you are interested in the exclusive customization service for enzymes, please do not hesitate to contact us.
Reference
- Joshi, RP.; Kumar, N. Artificial Intelligence for Autonomous Molecular Design: A Perspective. Molecules. 2021, 26(22):6761.


